Supercharging PostgreSQL with PgBouncer

As I’ve written about previously, Postgres is an incredibly rock solid database. What’s more, when the good vibes go your way and you need to scale Postgres, its august ecosystem answers the call quite nicely. In particular, PgBouncer enables you to both vertically scale Postgres and more efficiently take advantage of Postgres horizontal scaling.
PgBouncer is primarily a connection pooler and router for Postgres. It acts as middleware between applications and one or more Postgres instances, managing both routes to individual databases as well as a pool of connections. Leveraging PgBouncer can significantly improve the performance of an application by reducing the overhead of opening and closing new connections to the database as well as enabling you to easily route traffic to multiple Postgres instances (such as read replicas, for instance).
With PgBouncer managing database connections, you free up valuable resources for your database instances thereby enabling you to more efficiently vertically scale. Moreover, PgBouncer's routing features make it copacetically easily to route queries to multiple instances. In this way, PgBouncer is conceptually akin to a load balancer enabling efficient horizontal scaling.
Getting started with PgBouncer
Getting started with PgBouncer couldn't be any easier; in fact, I've set up a Github repository, dubbed Recoil, that'll enable you to familiarize yourself with both PgBouncer's connection pooling and routing features from the comfort of your laptop. All you need is Docker Engine and you'll be good to go, baby!
The connection pooling boogie
Connections in Postgres are expensive because Postgres creates a new backend process for each connection, which involves memory allocation and initialization tasks. A connection pooler manages a set of connections thereby freeing up a database's resources to focus on other aspects, such as rapidly returning data.
To see how PgBouncer works as a connection pool, you can use use pgbench, which is a simple command line utility that runs benchmark tests on a Postgres instance. It's an efficient way to exhaust database resources, which is easy do if you set a high value for pgbench's client connections (i.e. via the -c flag) . You can, of course, increase Postgres's max_connections; however, you'll potentially do this at the cost of other important resources.
Using the handy docker-compose.yml file found in the Recoil repository and following the detailed directions in the README, you can fire up a single instance of Postgres and do two things: initialize the database for benchmarking and then running a benchmark test.
Initializing the database for benchmarking is easy. Run the following command in your favorite terminal:
$ pgbench -i -s 5 -h localhost -p 49149 -U postgres recoilUsing pgbench to initialize the database before benchmarking.
The -i flag initializes a benchmark with a scale factor of 5 via the -s flag. This will create 500,000 rows in a ppgbench_accounts table.
By default, Postgres's max_connections is set at 100. You can quickly exhaust this resource by running a benchmark test that exceeds this limit like so:
$ pgbench -c 101 -j 2 -t 100000 -h localhost -p 49149 -U postgres -S recoilExhausting Postgres with 101 client connections.
In this case, 101 clients, configured via the -c flag were thrown at the local Postgres via 2 threads (i.e. -j). Each client attempted to issue 100,000 transactions via the -t flag. Unfortunately, this test fails as Postgres quickly exhausts valuable connections. The database will error out with a message along the lines of FATAL: sorry, too many clients already.
This is a great use case for employing a connection pool like PgBouncer! Following the groovy directions I outlined in Recoil's README you can stand up PgBouncer in front of Postgres and let it manage database connections; what's more, if you set PgBouncer's connection pool to a large number, such as 200, you can get through the above pgbench test without failure.
Accordingly, you can reissue the pgbench benchmark test pointing to a different port, since you're going directly to PgBouncer (instead of Postgres) like so:
$ pgbench -c 101 -j 2 -t 100000 -h localhost -p 5432 -U postgres -S recoilA successful pgbench test using PgBouncer.
Connection pooling isn't a panacea; indeed, you can play around with pgbench and quickly exhaust PgBouncer as well. What's important is that you've essentially offloaded connection management to a specialized process which is more efficient. Moreover, PgBouncer adds a few other handy features for your scaling needs including routing.
Routin' SQL requests
Horizontally scaling Postgres is fairly simple, especially if you read my blog post on read replicas. Of course, when you stand up more than one database, you'll want an easy way to route SQL requests. A simple load balancer would do this automatically for you; however, with PgBouncer, you can easily route via a name. In the case of read replicas, you'll want to route writes to the primary instance and reads to one or more replicas. Conceptually, the architecture of using PgBouncer as a combination pooler and router looks like so:
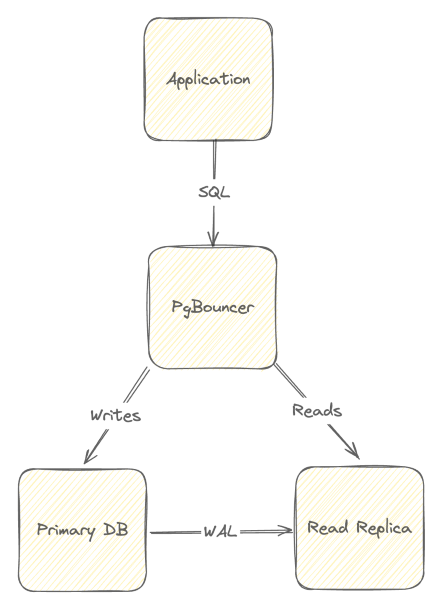
With PgBouncer, routes are configured like connection strings, where the database name signifies a specific database. For instance, in my Recoil example, the database is named recoil. In a normal read replica environment, read replicas would have the same name; nevertheless, with PgBouncer, you can give each read replica a unique identifier, which clients can leverage for specific routing.
You can see routing in action following the directions in the Recoil Github repository. If you examine the docker-compose.yml file, you'll note that the PgBouncer instance, pgbouncer, defines two databases. Defining the first database is done like so:
- POSTGRESQL_HOST=postgres-primary
- POSTGRESQL_PASSWORD=recoil
- POSTGRESQL_DATABASE=recoil
- PGBOUNCER_DATABASE=recoilPgBouncer environmental variables defining one database with a route named recoil.
Subsequent databases, however, are defined using a somewhat esoteric string like so:
- PGBOUNCER_DSN_0=recoil-ro=host=postgres-replica port=5432 dbname=recoilDefining a named route in PgBouncer.
The crucial part of this string is the DSN_0 aspect, which gives this route the name recoil-ro. This logical name points to the postgres-replica service listening on port 5432.
You can see routing (and replication too!) in action by using psql to log into the primary and issuing two SQL queries. First, shell into the primary using the following command:
$ psql postgresql://postgres:recoil@localhost:5432/recoilUsing psql to shell into the primary instance.
If you're following the directions in Recoil's repository and ran bunzip2 on the employee_data.sql.bz2 file and then started things up with docker compose up -d, then when you run this SQL command, you should see a count of 300024.
select count(*) from employees.employee;A SQL count of all employee rows.
Next, insert an additional employee record like so:
insert into employees.employee values (9999999999, '1987-03-21', 'Joe', 'Smith', 'M', '2022-01-22');Inserting a new employee.
With Postgres replication, behind the scenes this record is automatically added to the configured read replica (i.e. the postgres-replica service found in the Docker compose file). You can verify this new row was added by using psql to shell into the replica instance by referencing the route name elaborated earlier, which is recoil-ro.
$ psql postgresql://postgres:recoil@localhost:5432/recoil-roUsing psql to shell into the read replica instance using its logical name recoil-ro.
Run the aforementioned count query and you should see the answer is 300025, which reflects the newly added employee record inserted into the primary instance and replicated to the replica.
As you can see from the code above, PgBouncer is acting like a proxy, routing queries to appropriate database instances via name. In fact, conceptually, PgBouncer is akin to a load balancer. It does represent a single point of failure, but if you zoom out slightly, you'll recall that PgBouncer also is a connection pool.
Keep on truckin' with PgBouncer
If you're using Postgres and are looking for a way to improve the performance and stability of your application, then PgBouncer is a groovy option. It's easy to set up and use, and it can provide a significant improvement in performance. Can you dig it?
